We introduce VISUAL EMBEDDED INSTRUCTION (VIM), a new framework designed to evaluate the visual instruction following capability of Multimodal Large Language Models (MLLMs). VIM challenges the MLLMs by embedding the instructions into the visual scenes, demanding strong visual interpretative skills for instruction following. We adapt VIM to various benchmarks, including VQAv2, MME, MM-Vet, and RefCOCO series, compose a VIM bench, and probe diverse MLLMs across three distinct in-context learning settings: Zero Shot, One Shot, and Pair Shot. We observe that there is a significant performance disparity between the open-source MLLMs and GPT-4V, implying that their proficiency in visual instruction comprehension is not up to par. Our results highlight a promising direction for the enhancement of MLLMs capabilities on instruction following. We aim VIM to serve as a useful norm for advancing the state of the art and driving further progress in the field.
Instruction following, is viewed as one key capability of high-performing MLLMs. In this work, VIM is created to examine the instruction following capability of MLLMs, specifically the visual embedded instruction following.
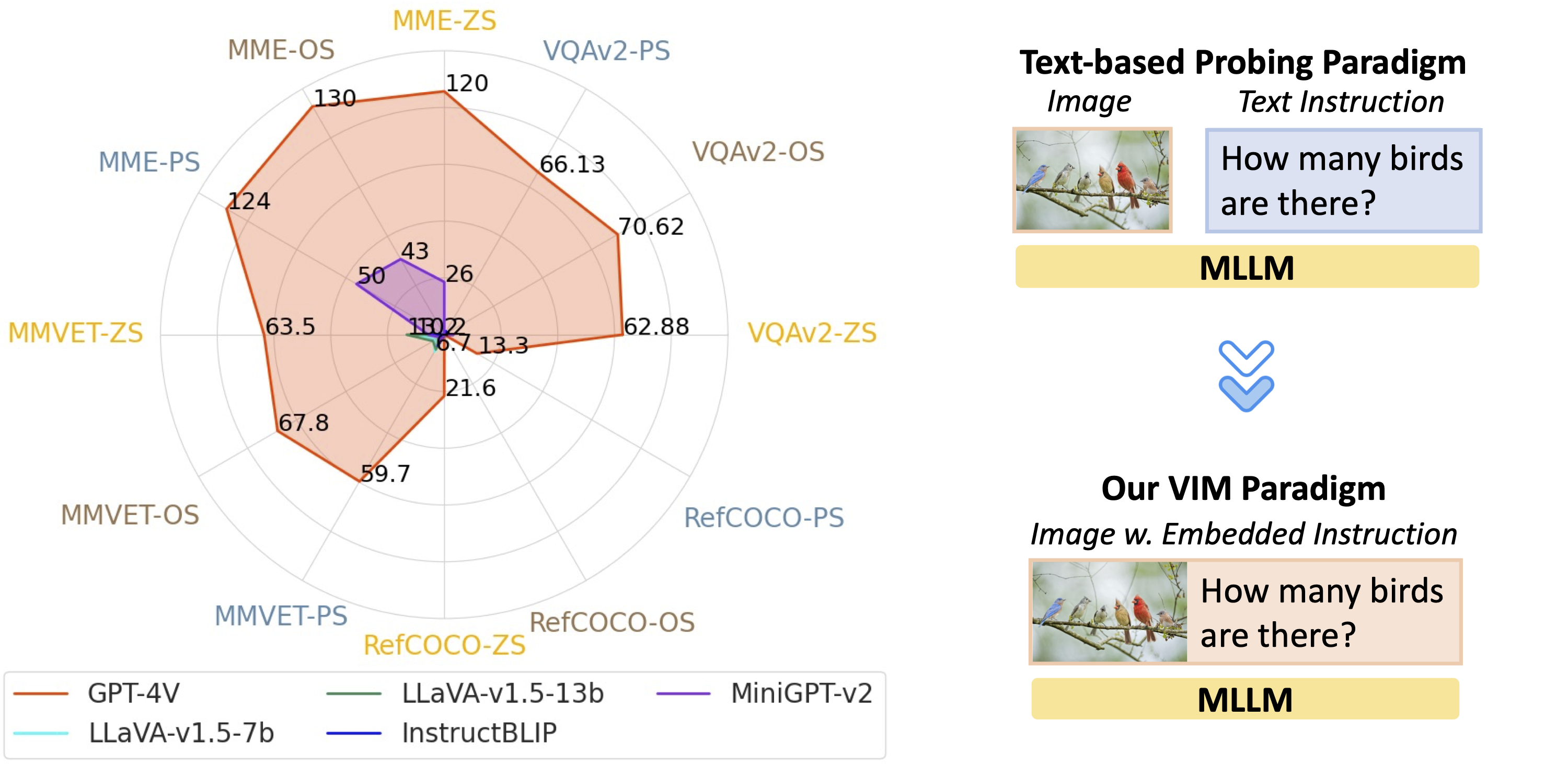
The current evaluation norm of MLLMs takes two modalities as input: image and text (as instruction). The existing MLLMs is built on top of the LLMs, benefiting from its strong text understanding capability. For the current MLLMs evaluation paradigm, instruction is presented in the text modality, which can utilize the strong language priors from the LLMs for understanding. VIM takes one step further by embedding the textual instruction into the visual space (image), this enhancement demands not just textual but also strong visual comprehension for the instruction understanding. It asks for the strong visual interpretation capability to recognize and follow the embedded instruction in the image.

Zero shot evaluation paradigm comparison for MLLMs. (a) Left: Image + Text instruction as two separate modalities are fed into MLLMs for inference; (b) Right: VIM only takes the image modality with the text instruction embedded in the image , no additional text prompt is required. The above example is from MM-Vet (question #86). Note: Image modality input , Text modality input.
Under the VIM framework, we also propose three in-context learning settings designed to probe the MLLMs models across a spectrum of challenges as depicted in below Figure.

Three in-context evaluation settings: (a) Left: Zero Shot has only one question to be answered; (b) Middle: One Shot, the image is composed of one image-instruction-answer as a reference, the answer for the second image-instruction query is required; (c) Right: Pair Shot, the image is composed of two image-instruction pairs, and answer for both are required.
We first build our VIM bench based on the existing representative benchmarks (e.g., VQAv2, MME, MM-Vet, REC), then examine the MLLMs (e.g., LLaVA-v1.5, InstructBLIP, MiniGPT-v2, GPT-4V) on VIM bench for fair comparison.
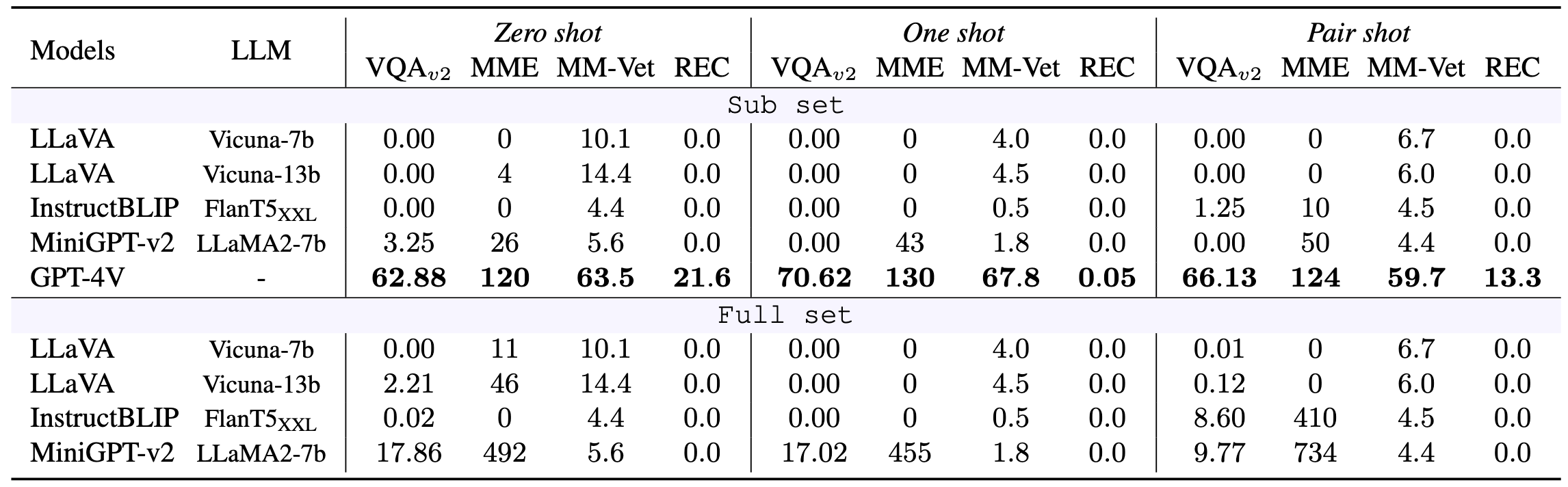
Main quantitative results over each benchmark, including sub set and full set for three settings.
How to lay out the image and embedded instruction in one visual space? There are many combinations to position the instruction and image in the same visual space. Here we also enumerate important two elements we investigated: 1) instruction location, 2) prompt type.

Left: Exploration setup for instruction location on zero shot evaluation for MM-Vet. Right: Exploration setup for text prompt on zero shot evaluation for MM-Vet. * denotes from the origin paper reported.
@misc{li2024text,
title={Text as Images: Can Multimodal Large Language Models Follow Printed Instructions in Pixels?},
author={Xiujun Li and Yujie Lu and Zhe Gan and Jianfeng Gao and William Yang Wang and Yejin Choi},
year={2024},
eprint={2311.17647},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@misc{lu2023vim,
title={VIM: Probing Multimodal Large Language Models for Visual Embedded Instruction Following},
author={Yujie Lu and Xiujun Li and William Yang Wang and Yejin Choi},
year={2023},
eprint={2311.17647},
archivePrefix={arXiv},
primaryClass={cs.CV}
}